Evening all, I trust this post finds you well.
You might’ve been able to guess, or you might’ve just assumed, but yes, I am enrolled in the Windows Insider Program. It was pretty fun throughout Windows 10’s development and even after the initial release, culminating in the very recent roll out of “TH2” or “the real Windows 10”. There’ve been a few stutters along the way, odd glitches and issues, but here’s one that popped up recently and has been annoying me a little…
I’m sure you’re all familiar with the shortcut arrow; To denote an icon is a shortcut a small arrow is overlayed in the bottom left corner, which looks a bit like this:
That’s nice – but I always disable it, I find it makes my screen too cluttered. There are more of these overlay icons too, for shared files/folders for example, and third party apps can add their own too, like TortoiseSVN showing if your repository is up to date.
Somewhere in the recent TH2 builds a new overlay was introduced to indicate compressed files/folders. This looks like a pair of blue arrows pointing at each other, and is placed in the top right, like so…

Houston, we have annoying icons
This new icon overlay seems to pop up fairly randomly. I’m guessing it’s not a bug, and that it really is displaying compression status of the file in some way, but it has some odd and inconsistent behaviour when applied to shortcuts which lead to, well, situations like this…
I just clean installed Windows 10 1511 and I’ve only gotten a few applications installed. If the app gives you a choice, I point them to install on my second hard drive rather than the small SSD I run Windows from, so nearly all the app shortcuts point to the same place, yet VMWare and the Adobe applications on my taskbar have this compressed overlay while FileZilla and WinRAR don’t despite them being in the same compressed directory, right alongside each other.
Why? I have no idea, but it’s really annoying. Plus, even if this odd shortcut behavior was fixed, I still wouldn’t want to see these icons. If I wanted an indication of compressed files I’d probably have already changed their label text colour.
I Google’d the issue a bit, figuring someone would’ve packaged up a solution by now. I found lots of people talking about it, but no actual answers beyond “decompress those files”. So I got to work.
Playing Detective
This was really pretty simple. I knew how to remove shortcut arrows already – all you need to do is put a blank icon file somewhere on the PC, then make a little registry change to make Windows display this blank image instead of the normal shortcut arrow. It’s never really removed, just made totally see-through. There are numerous utilities that perform this process and hide the arrows for you, for this and a few other little post-install touches I usually use Ultimate Windows Tweaker.
The registry value needed to remove the shortcut overlay is a string (REG_SZ) called “29” with the value being the path to the empty icon followed by the icon offset. Since I always copy the empty icon to System32, my value is just “empty.ico,0“.
Working under the assumption this new icon could be overridden in the same way just with a different numeric name for the string, I grabbed ProcMon from SysInternals which allows you to monitor exactly what everything on your PC is doing, including calls to the registry. You can also set filters in ProcMon, so I created a filter that would exclude everything *except* calls to the specific registry key where the shortcut arrow fix is applied. One quick restart of Explorer in Task Manager so it would try to reload all possible values from the registry, and I had a set of 10 or so ID numbers, one of which should be the compression icon ID.

Armed with this knowledge I started a Windows 10 virtual machine and tested each ID, resetting Explorer every time to test it’s effect. Turns out, “179” was the magic number.
I’ve created a small download so you can apply this to your own PC. There’s a ZIP document linked just below which contains the empty icon, two registry modifier files that will apply and revert the icon change, and a batch file which will copy the empty icon to your System32 folder and apply the registry modification for you – just right click and “Run as Administrator“.
Or, if you want to do this all yourself, here’s the contents of the registry modifier file. Just save this in a file with the .reg extension.
Windows Registry Editor Version 5.00 [HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Explorer\Shell Icons] "179"="empty.ico,0"
For everyone else, here’s the download link.
Extract the ZIP file somewhere and, for a quick fix, right click the run.cmd file and choose “Run as Administrator” near the top of the menu. If there are no errors (like the image below), either restart Explorer, log off and on again, or restart the PC for the change to take effect.
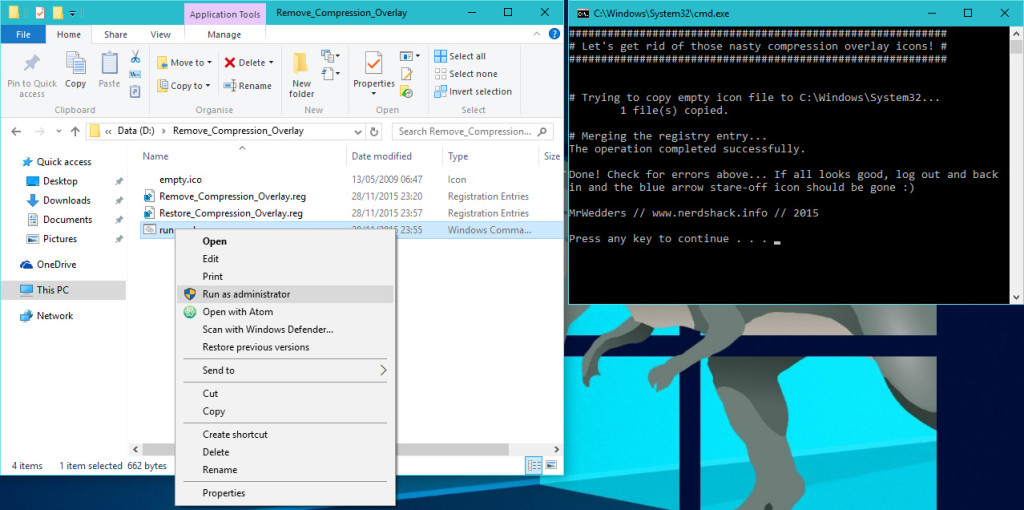

You could also copy the empty icon file manually, and double click the Remove_Compression_Overlay.reg file to add the registry entry.
Should you want to revert this change and make the icon overlay visible again, use the Restore_Compression_Overlay.reg.
No doubt some established utilities will pick up support for this feature soon, but until then this little fix should do it.
Thanks for reading, and enjoy your arrow-free PC experience!
— Ben